


Los científicos de datos son responsables de analizarlos, crear modelos estadísticos y predictivos que permitan anticipar comportamientos y extraer el valor de los datos.
Según las estadísticas elaboradas en la Unión Europea, en 2016 existían unos 6 millones de empleos relacionados con los datos en toda la Unión Europea. Aun con estas cifras, la demanda de científicos de datos en la Unión Europea roza en la actualidad el medio millón de puestos de trabajo, con previsiones de alcanzar una escasez de 800.000 puestos en 2020. ¿Por qué sucede esto?
Dentro del mundo big data, existen diferentes puestos profesionales que dependen de sus tareas en el ciclo de datos. En general, se suele hacer distinción entre dos perfiles:
Los ingenieros de datos, responsables de los procesos de capturar datos en las infraestructuras y de la propia operativa de las mismas.
Los científicos de datos, responsables de analizarlos, crear modelos estadísticos y predictivos que permitan anticipar comportamientos y extraer el valor de los datos.
El ingeniero de datos
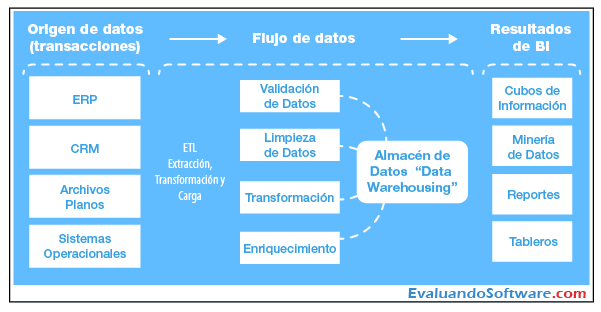
Las aptitudes necesarias en los ingenieros de datos son de perfil puramente técnico, y deben ser profundos conocedores de las tecnologías de almacenamiento, captura y procesamiento del big data. Esto implica el conocimiento de lenguajes de programación adecuados y con funcionalidades de big data, herramientas que ayudan a realizar procesos de migración de datos y transformación (procesos extract-transform-load, ETL), así como herramientas de extracción de datos, una vez están en este tipo de infraestructuras. Todo ello tiene poca relación con el core de negocio de las empresas al tiempo que demandan un componente técnico fundamental. Aunque estas tecnologías son relativamente modernas, la adaptación de profesionales del mundo del desarrollo de aplicaciones o la gestión y la utilización de bases de datos tradicionales se puede realizar de manera ágil, adquiriendo el conocimiento sobre estas tecnologías.
El científico de datos
En el perfil más analítico —el científico de datos— se mezclan distintos tipos de conocimiento. Para utilizar las infraestructuras donde se almacena el big data es necesario conocer lenguajes de programación y de extracción de datos, aptitud que se adquiere en carreras como Ingeniería Informática o de Telecomunicaciones.
Por otro lado, es necesario el conocimiento de las herramientas estadísticas y matemáticas que permitan encontrar patrones en los datos o generar modelos predictivos, habilidades que han estado tradicionalmente repartidas entre diferentes carreras. Además de lo técnico, se suele requerir conocimiento del negocio, capacidades de comunicación y de gran entendimiento del cliente, lo que hace que el perfil de estos profesionales sea muy escaso, fundamentalmente por dos razones: en primer lugar, porque tradicionalmente no ha habido carreras universitarias que abordaron de manera unificada todas estas actitudes y, aunque ahora sí existen, las nuevas generaciones de profesionales todavía se están formando o tienen poca experiencia; en segundo lugar, contrariamente al perfil de ingeniero de datos que, aunque costoso, puede tener una fuente de profesionales reconvertidos de otros puestos relacionados con la gestión de bases de datos, es mucho más difícil formar a profesionales ya cualificados en algunos de los aspectos, ya que los requisitos son de naturaleza muy diferente.

Dentro de las actividades que llevan a cabo los científicos de datos, se engloban las siguientes:
Análisis descriptivo
La aplicación de técnicas estadísticas que permiten extraer características generales de un conjunto de datos.
Análisis predictivo
La utilización de técnicas procedentes del aprendizaje automático (una rama de la inteligencia artificial) para, a partir de los patrones históricos de los datos, calcular de manera automática por estos algoritmos una serie de modelos matemáticos que, ante nuevos datos, son capaces de pronosticar el futuro.
Análisis prescriptivo
En muchas ocasiones no es suficiente el aporte de predicciones, pues, para implementar un sistema completamente inteligente, los algoritmos deben proporcionar, además, la acción recomendada.
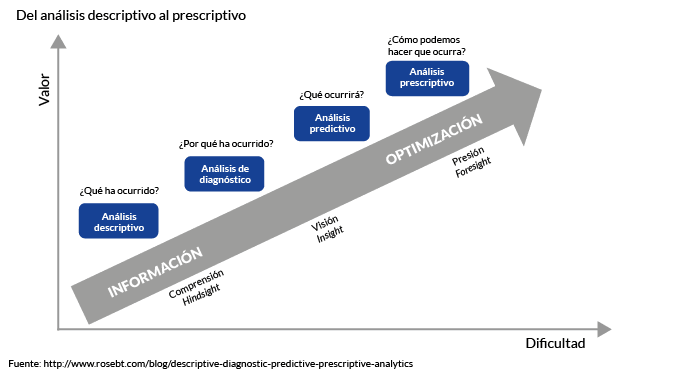
Recurriendo a un ejemplo de comercio online: a partir de los datos de navegación de la compañía, se pueden detectar puntos de fuga en el proceso de compra y, con ello, tomar decisiones sobre el diseño de la página web (análisis descriptivo); en otra fase del proyecto puede generarse una puntuación sobre la probabilidad de que un cliente cause baja en el servicio (análisis predictivo). Si además otro algoritmo dice el canal a través del cual debe contactarse con los clientes que van a abandonar (email, teléfono, visita presencial, oferta, etc.) para retenerlos con una mayor probabilidad de éxito, el círculo de la toma de decisiones de manera automática se cerrará (análisis prescriptivo).
Puesto que para llevar a cabo este tipo de análisis se requieren aptitudes diversas dentro de competencias informáticas, matemáticas y de conocimiento del negocio, hoy en día existe una necesidad muy alta de formación especializada, al menos, en tres vertientes diferentes:
1. Formación que genere científicos de datos profesionales.
2. Formación de científicos de datos líderes: profesionales que, aunque no precisen conocer el detalle técnico de los algoritmos, sean conscientes de su complejidad, de las métricas que se pueden calcular y de su rendimiento con la suficiente experiencia para aplicar sus resultados al negocio.
3. Formación y cultura del dato para ejecutivos: la utilización de los datos es un cambio cultural en las empresas que modifica la forma de abordar los problemas y que mueve un paradigma de toma de decisiones basadas en el conocimiento experto más racional, a partir de la evidencia estadística. Es por ello que, aunque no sean los responsables de los equipos de data science, deben de ser capaces de definir sus necesidades y hacerlo en términos de datos, analítica y predicciones.









